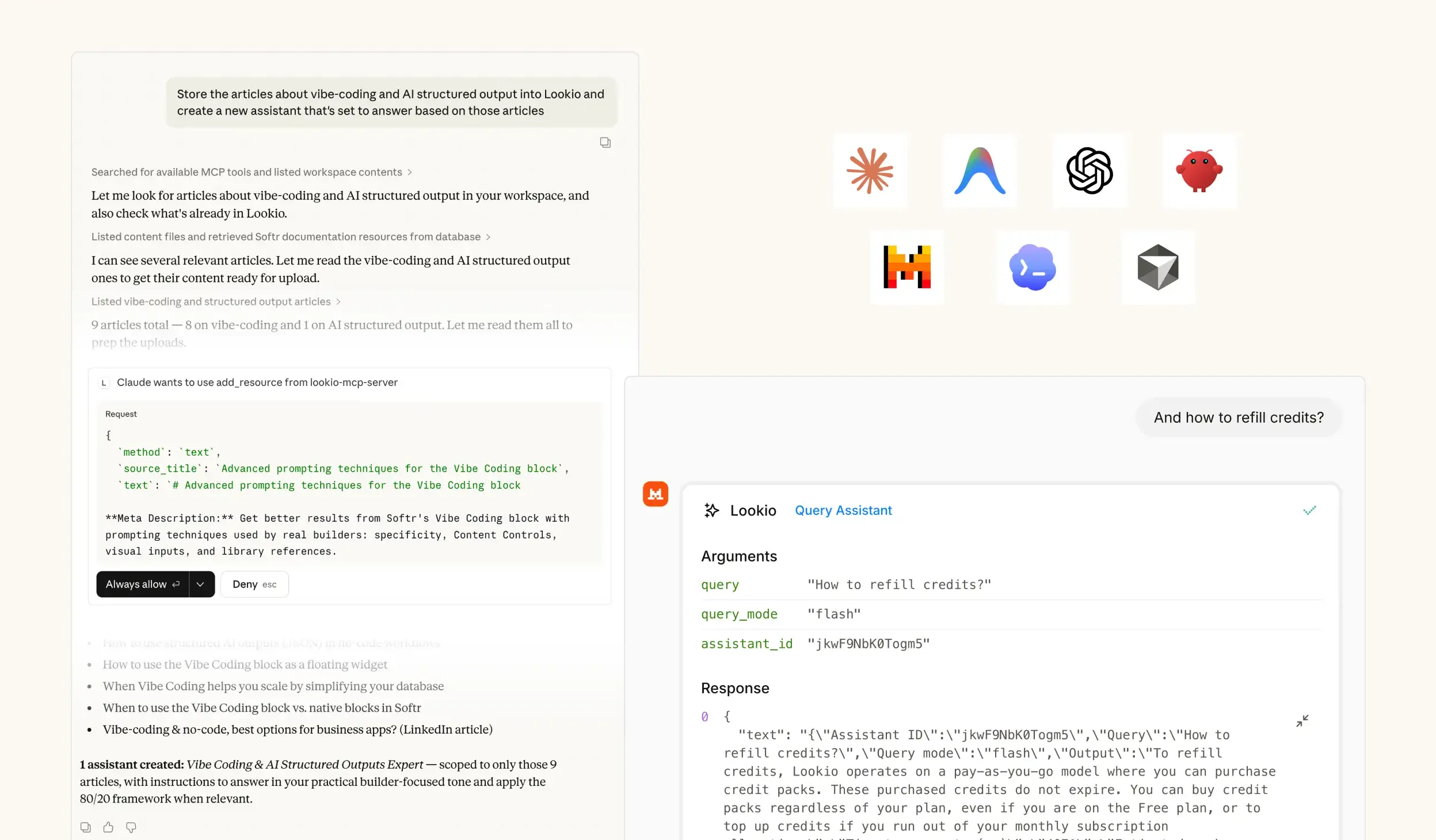
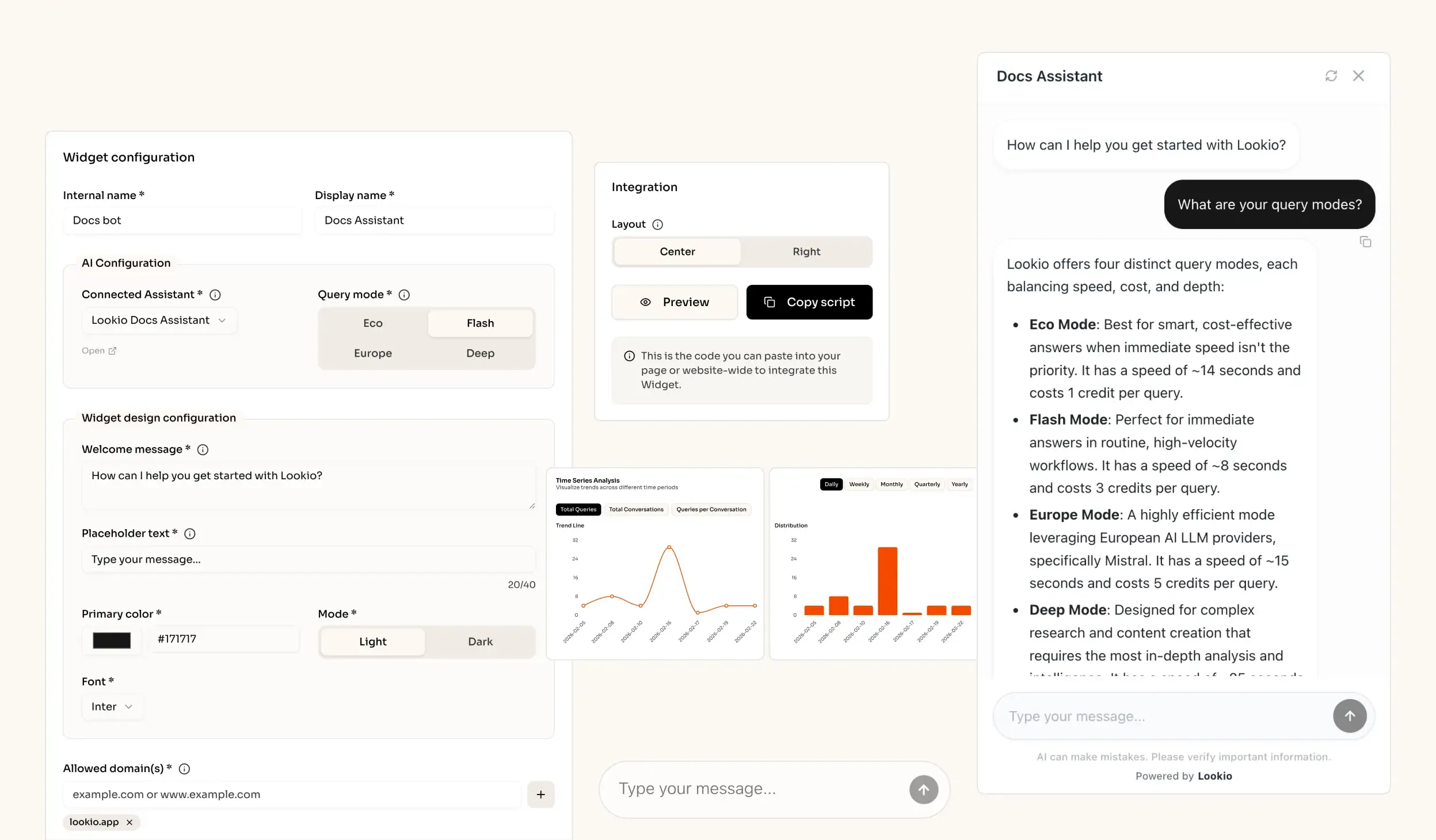
The challenge of scaling customer support teams
When a support team tries to maintain high quality while ticket volumes surge, they inevitably hit the knowledge bottleneck. Even the best-trained agents spend up to 20% of their day hunting through internal wikis, old Slack threads, or outdated PDFs to find a specific technical answer. This manual search isn't just slow; it's the primary cause of inconsistent support and missed SLAs.
The daily cost of locked knowledge
In a typical support workflow, information is often siloed across different platforms. When a customer asks about a specific edge case or a legacy feature, the agent must either guess, which leads to costly misinformation, or interrupt a senior engineer. These expert interruptions are expensive and pull your most valuable technical resources away from product development. Without a central, searchable brain, your support capacity is strictly limited by the number of humans you can hire and train.
Why the tools they've tried fall short
Most teams have already attempted to solve this with basic tools, but they quickly hit the ceiling of what standard tech can do:
- Helpdesk search and internal wikis: These rely on keyword matching. If the user doesn't use the exact technical term found in the document, the search returns zero results, leaving the agent stranded under pressure.
- Generic AI (like ChatGPT): While fast, generic LLMs are prone to hallucinations. They will confidently invent features or policies that don't exist because they aren't grounded in your specific documentation. This poses a massive brand and security risk.
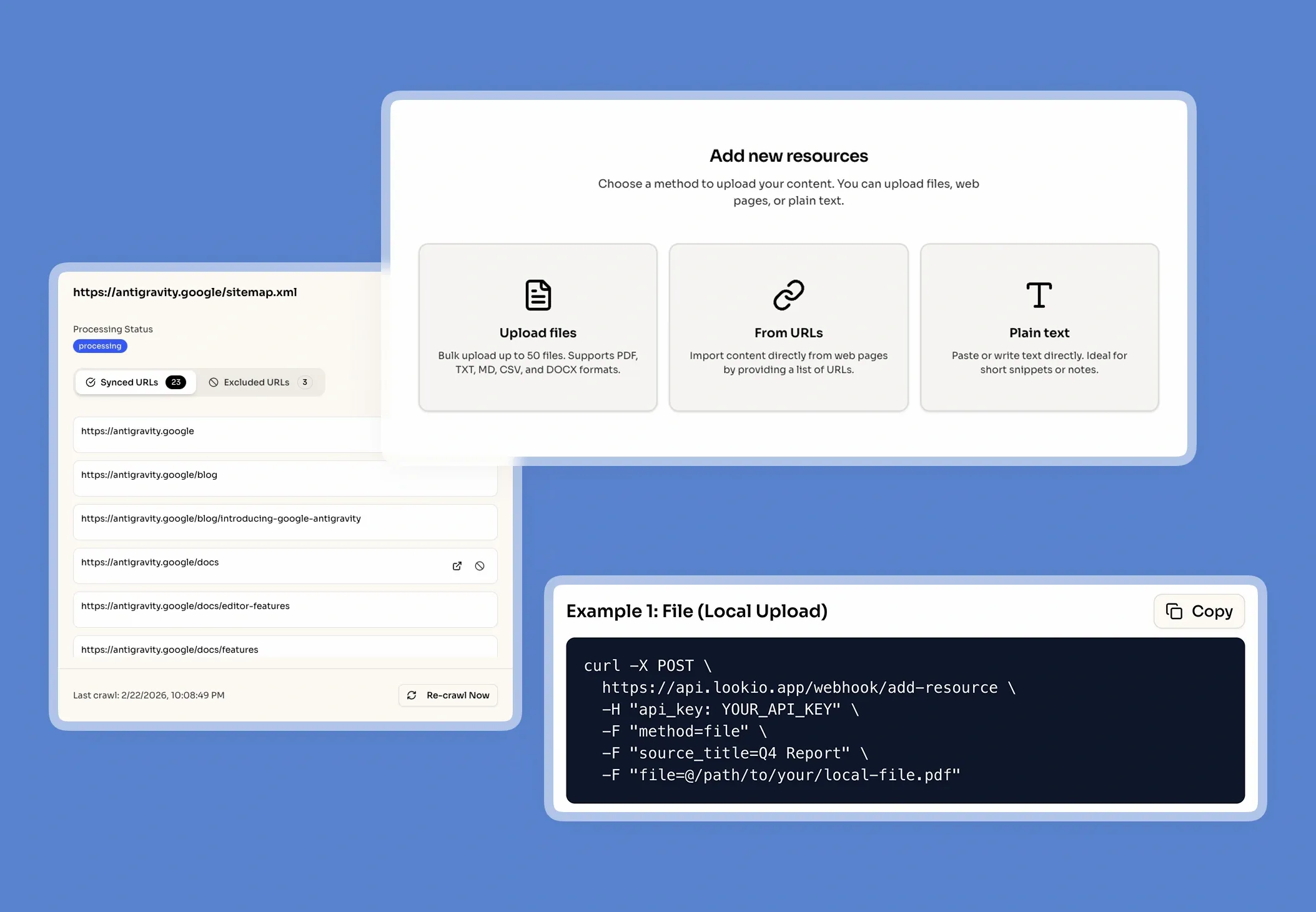
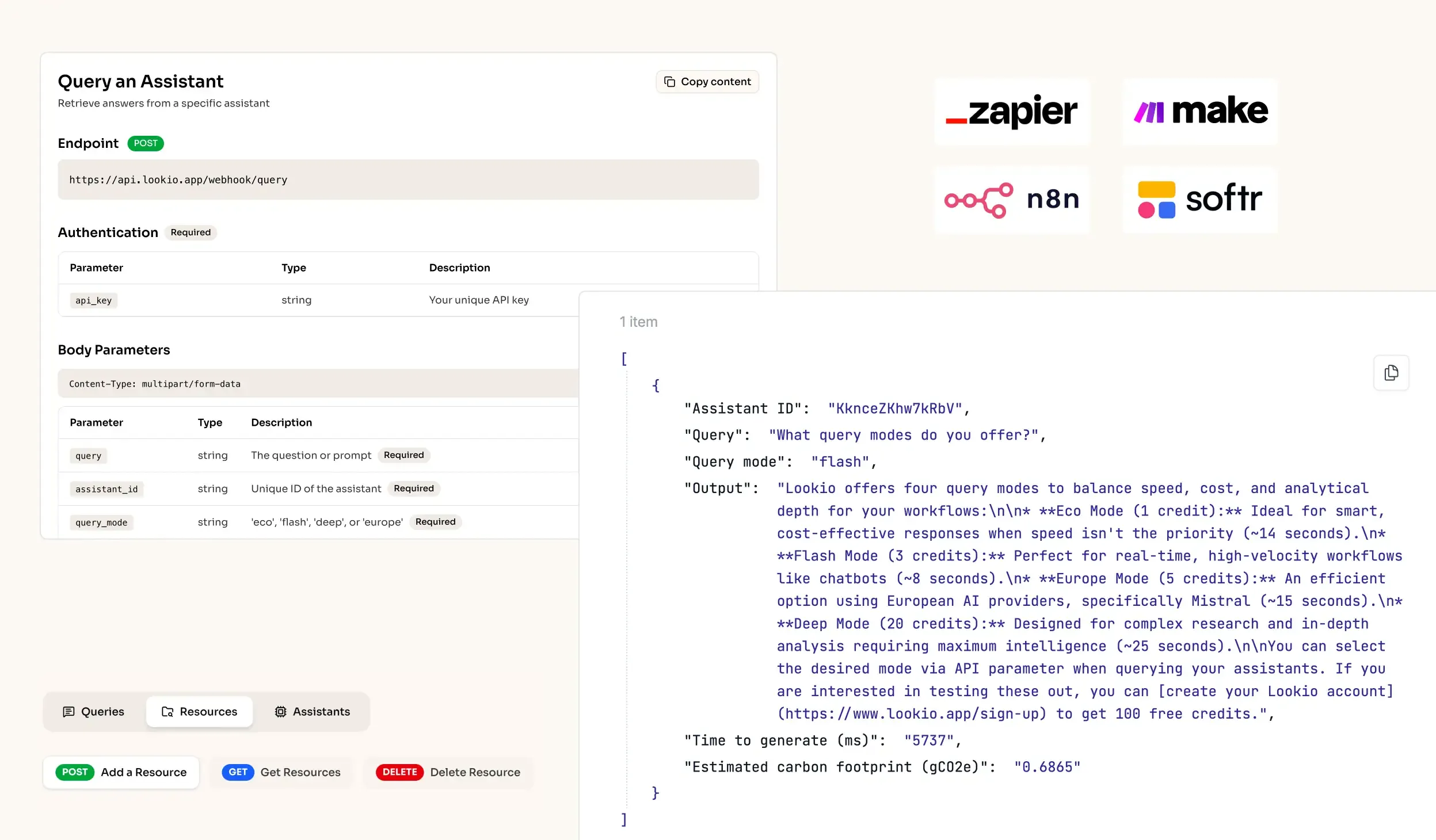
- No-API tools: Solutions like Google NotebookLM provide great retrieval for individuals, but they lack the programmatic access needed to scale. You can't connect them to your ticketing system or a live chat widget, making them useless for a professional AI support chatbot workflow.
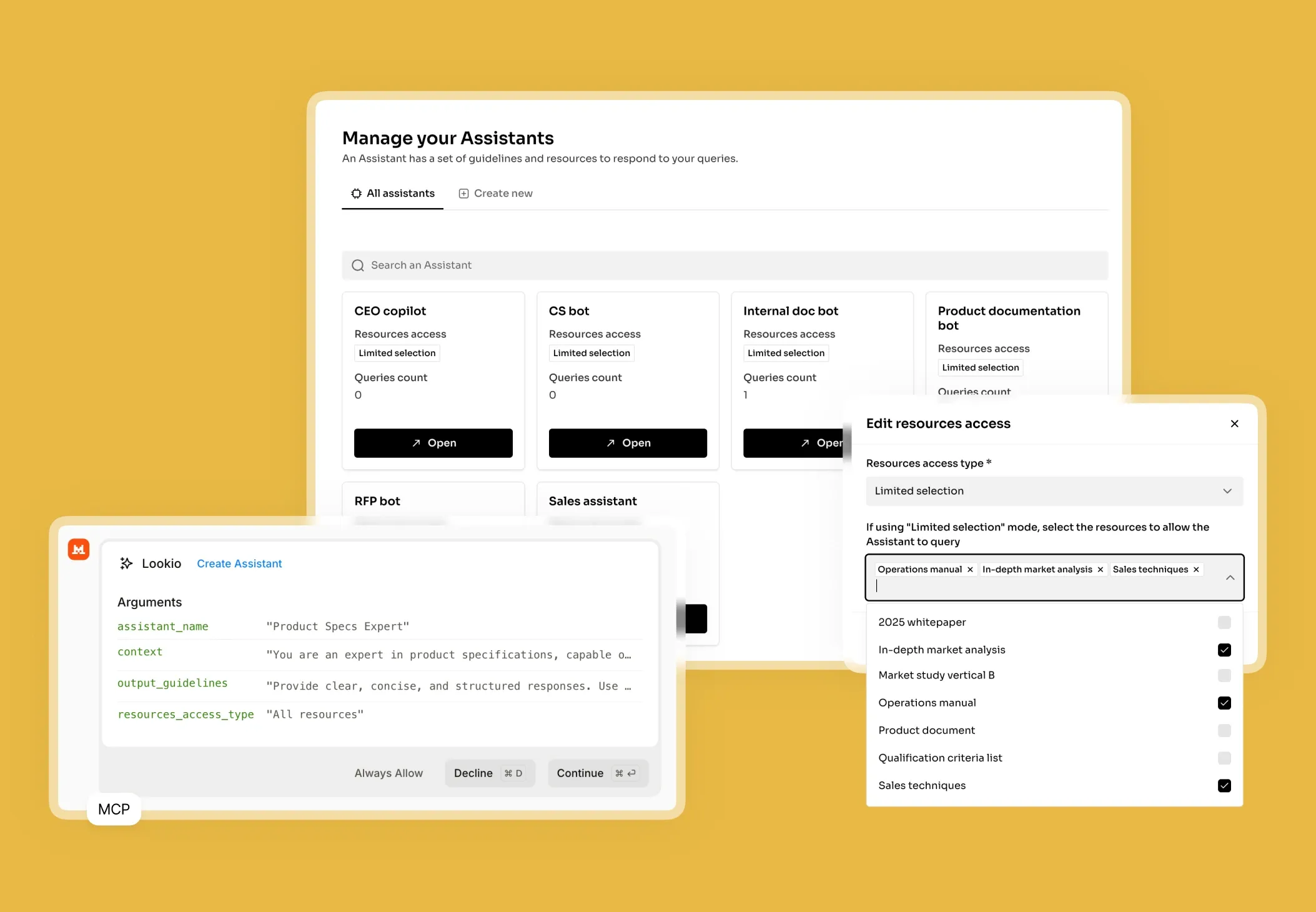
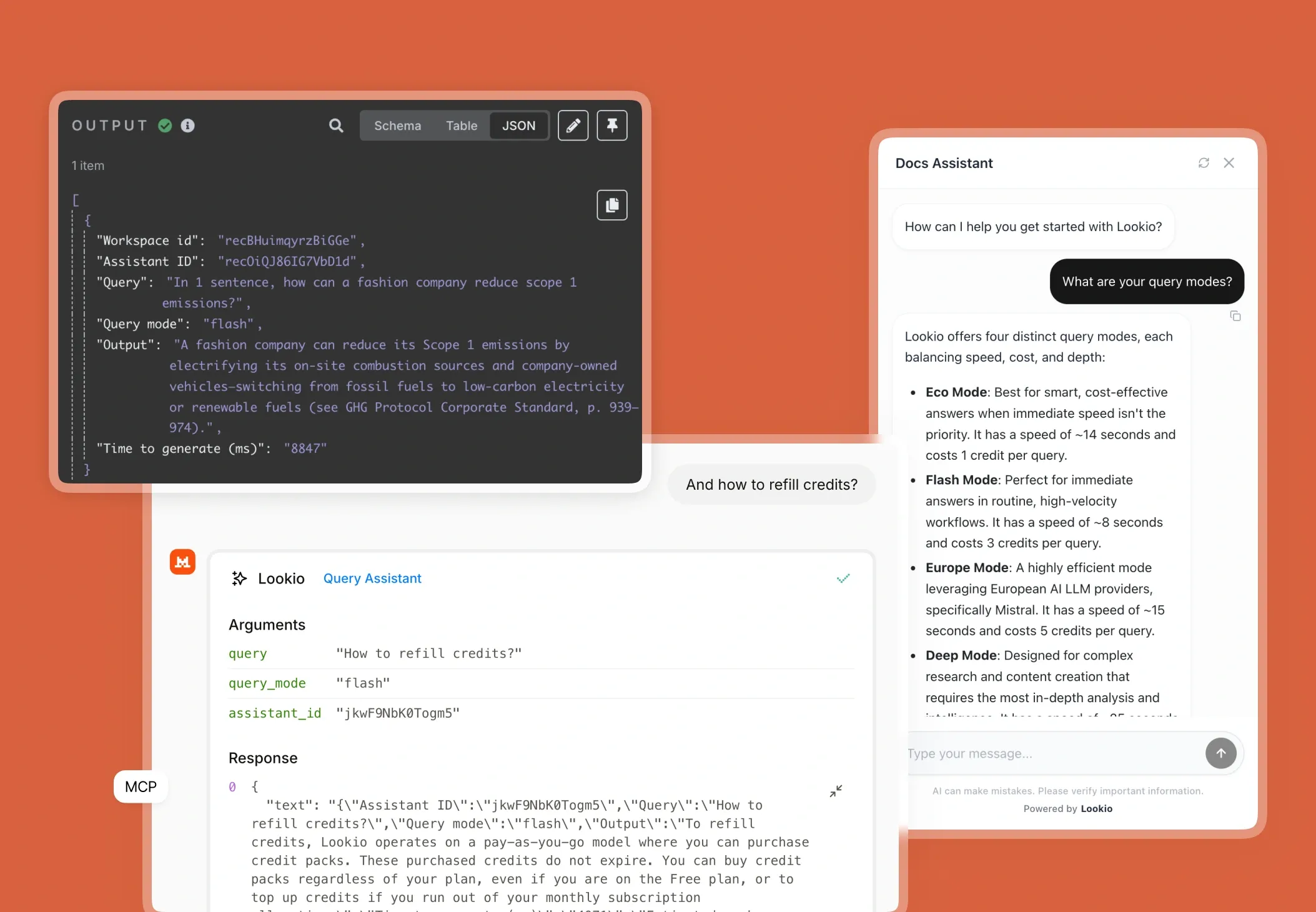
What's missing is a way to give your AI direct, programmatic access to your private knowledge base, ensuring every answer is sourced and verified.