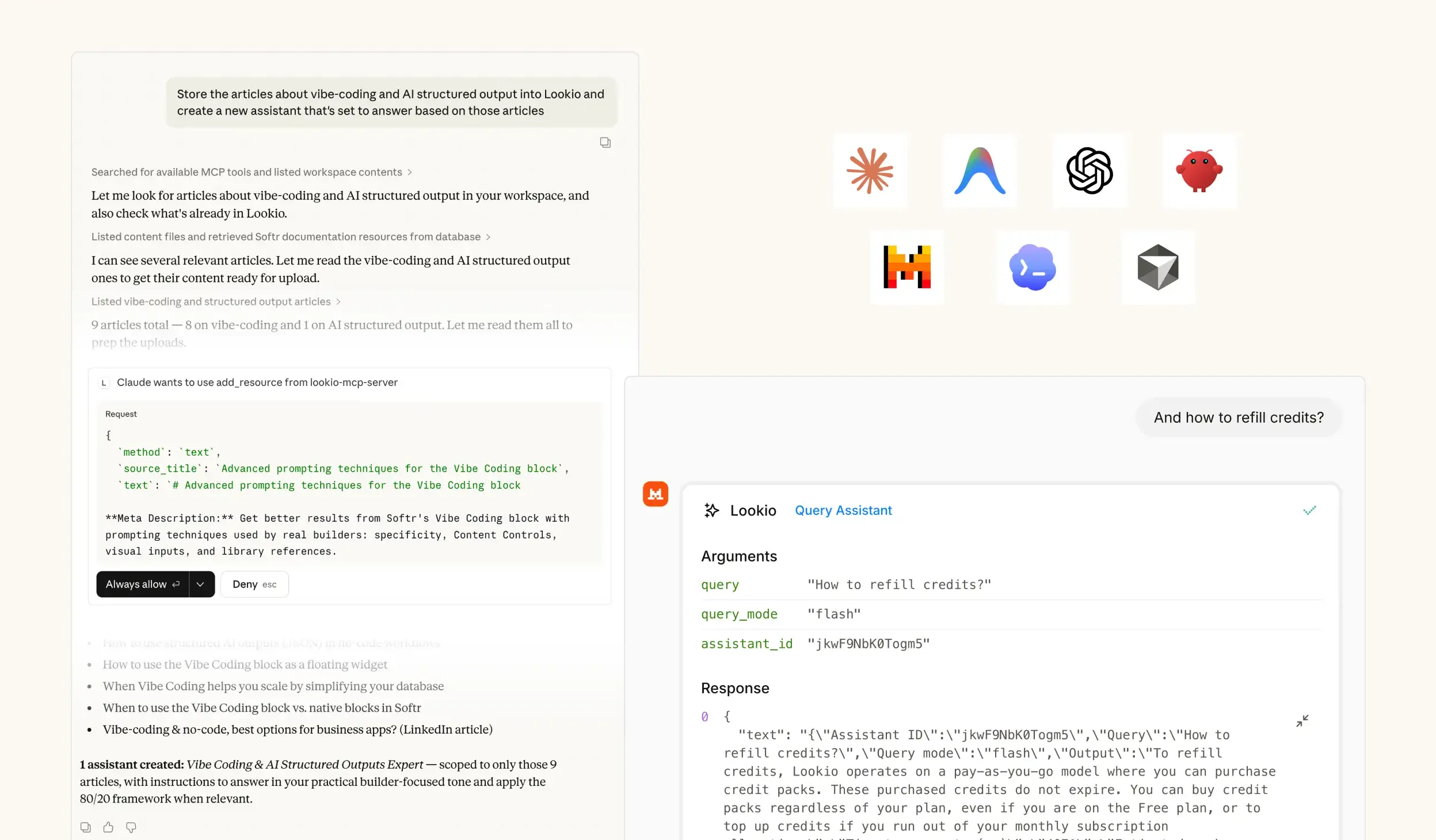
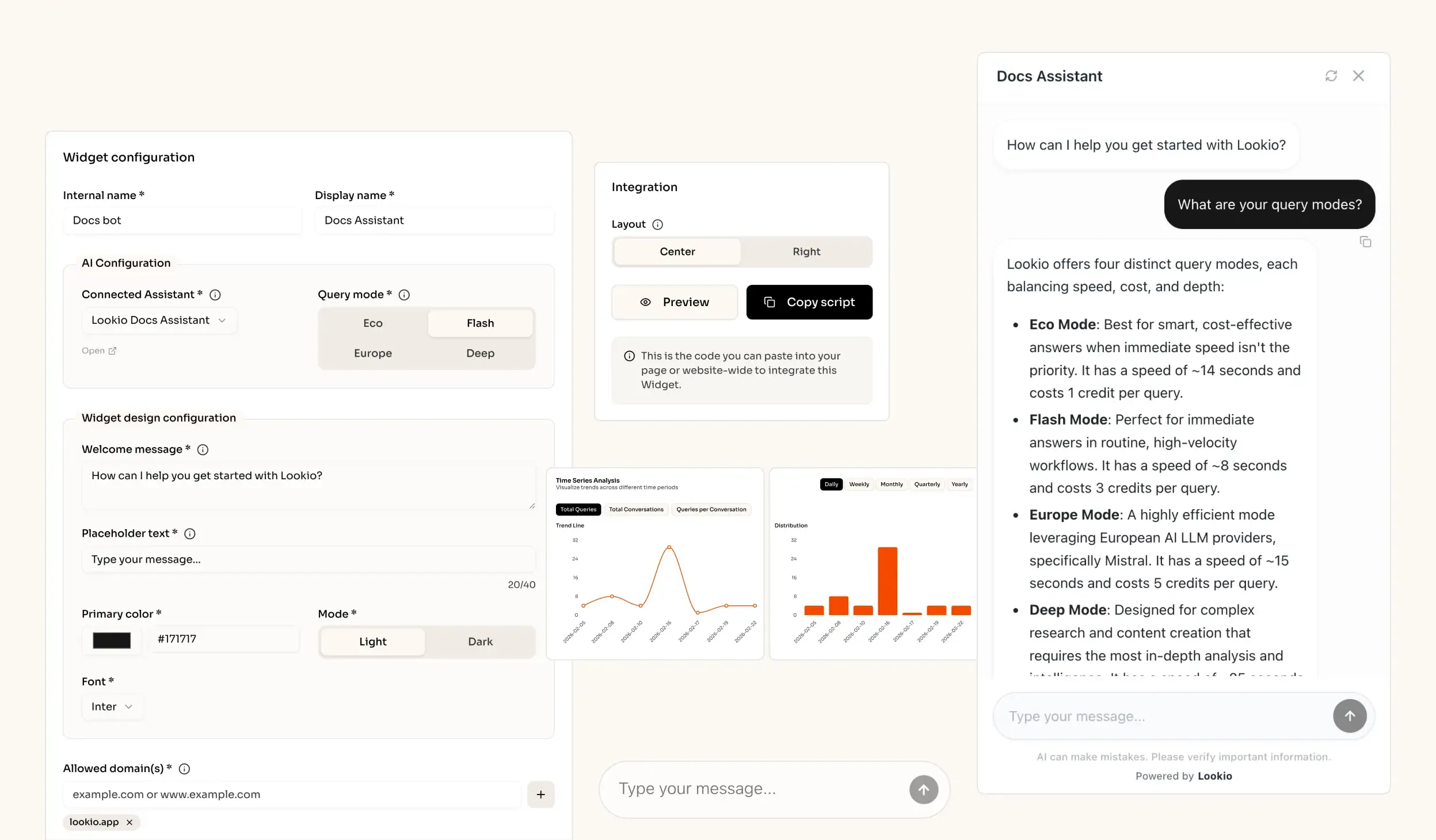
The challenge of fragmented engineering knowledge
When a developer or systems engineer tries to debug a legacy service or onboard onto a new codebase, they hit a wall of fragmented information. Architectural decisions are buried in old Slack threads, deployment steps are hidden in outdated Markdown files, and critical edge cases exist only in the heads of senior architects. The result is a constant state of flow-state interruption where experts are pinged repeatedly for the same answers.
The daily cost of technical silos
In a fast-moving engineering environment, the cost of information retrieval is paid in deteriorating velocity. When a junior engineer spends three hours hunting for a specific integration parameter that isn't in the main Readme, it pushes back sprint goals and puts SLA commitments at risk. These quality gaps lead to redundant work—teams end up rebuilding internal tools simply because they couldn't find the documentation for the existing ones. This isn't just a convenience issue; it is a bottleneck to scaling your technical team.
Why the tools they've tried fall short
Most engineering teams have already attempted to fix this with a mix of tools that ultimately lack the infrastructure for production-grade retrieval:
- Internal wikis and keyword search: Tools like Confluence or Notion rely on basic keyword matching. If you don't use the exact technical term, the search fails. They don't understand the semantic intent of a query like "how do we handle rate limits in the legacy auth service?"
- Generic LLMs (ChatGPT): While useful for boilerplate code, they have zero context regarding your private repositories or infrastructure diagrams. Pasting sensitive architecture docs into a public AI is a massive security risk, and their context windows collapse when you try to feed them entire system manuals.
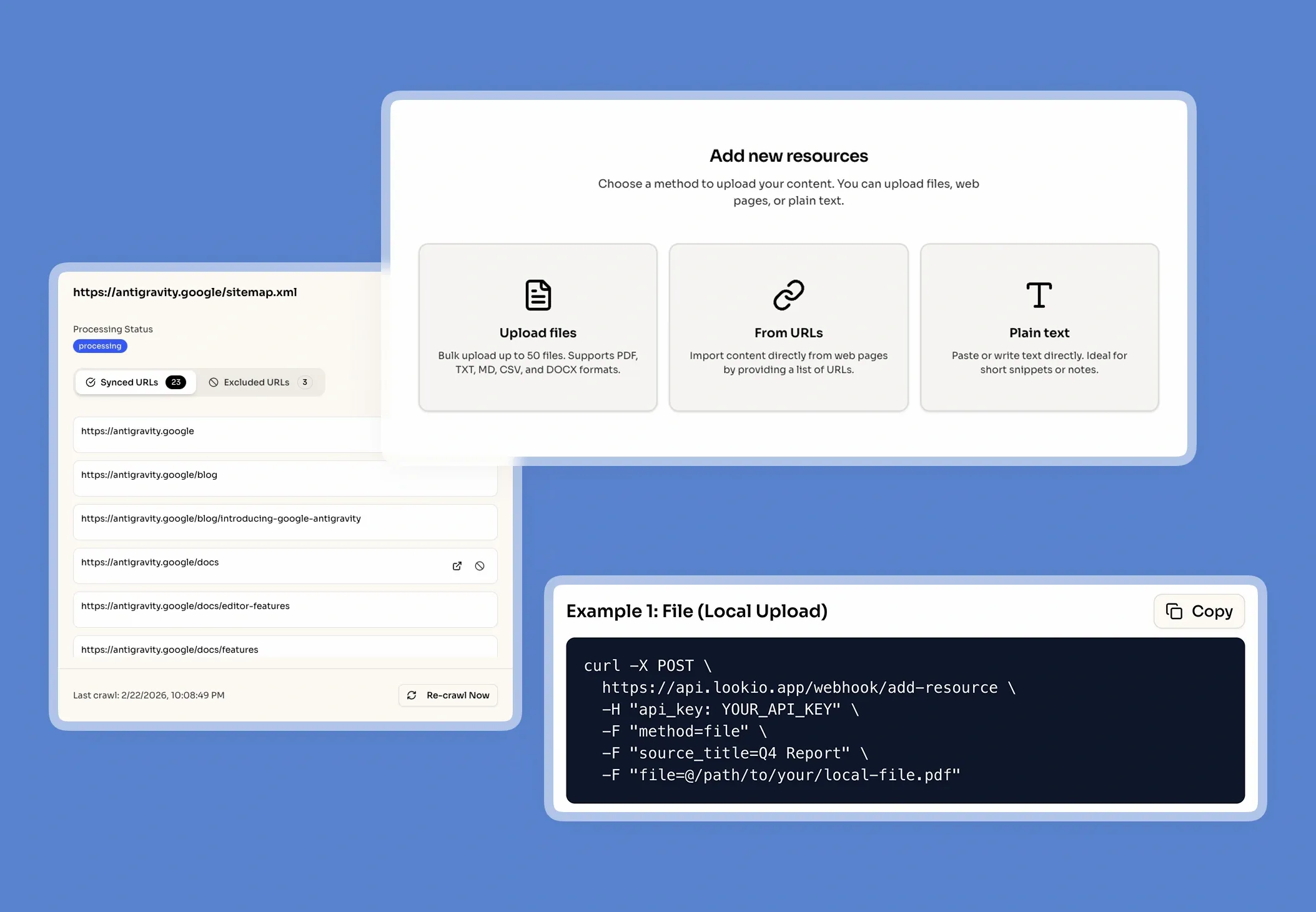
- Manual Context Loading (NotebookLM): Research tools are great for individuals, but as the NotebookLM API doesn't exist, they cannot be integrated into your
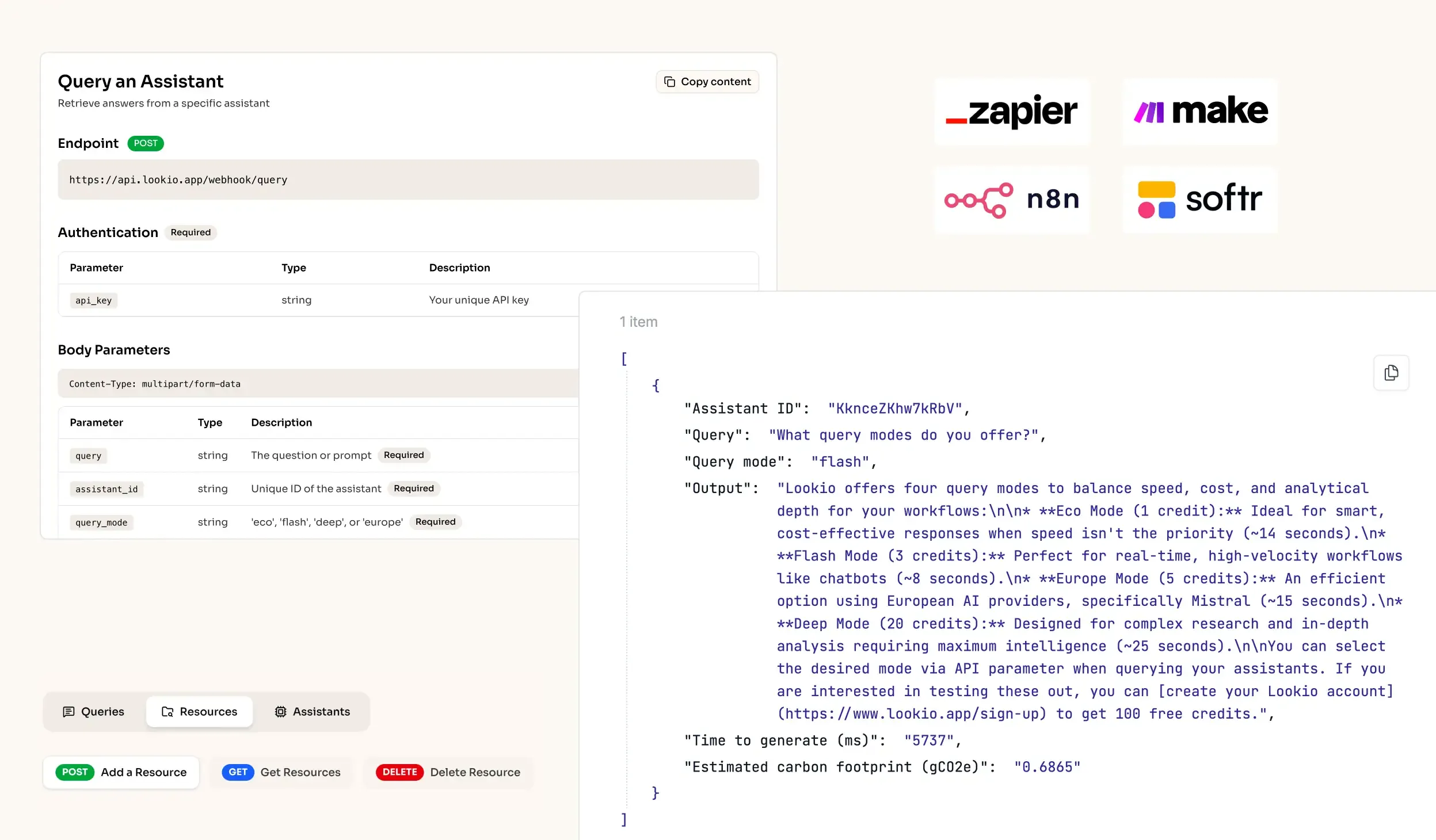
CI/CDlogs,IDEplugins, or automated ticketing systems.
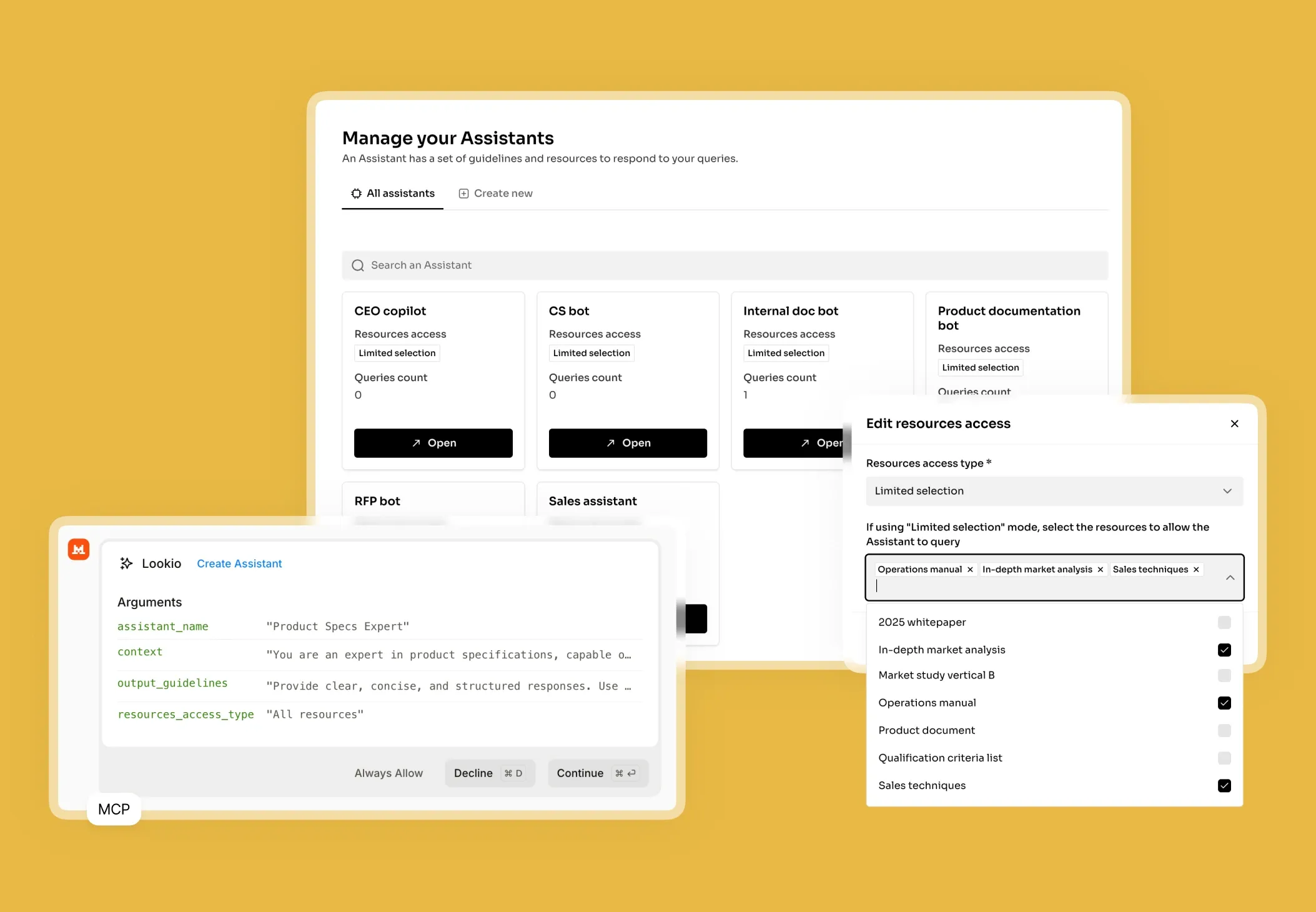
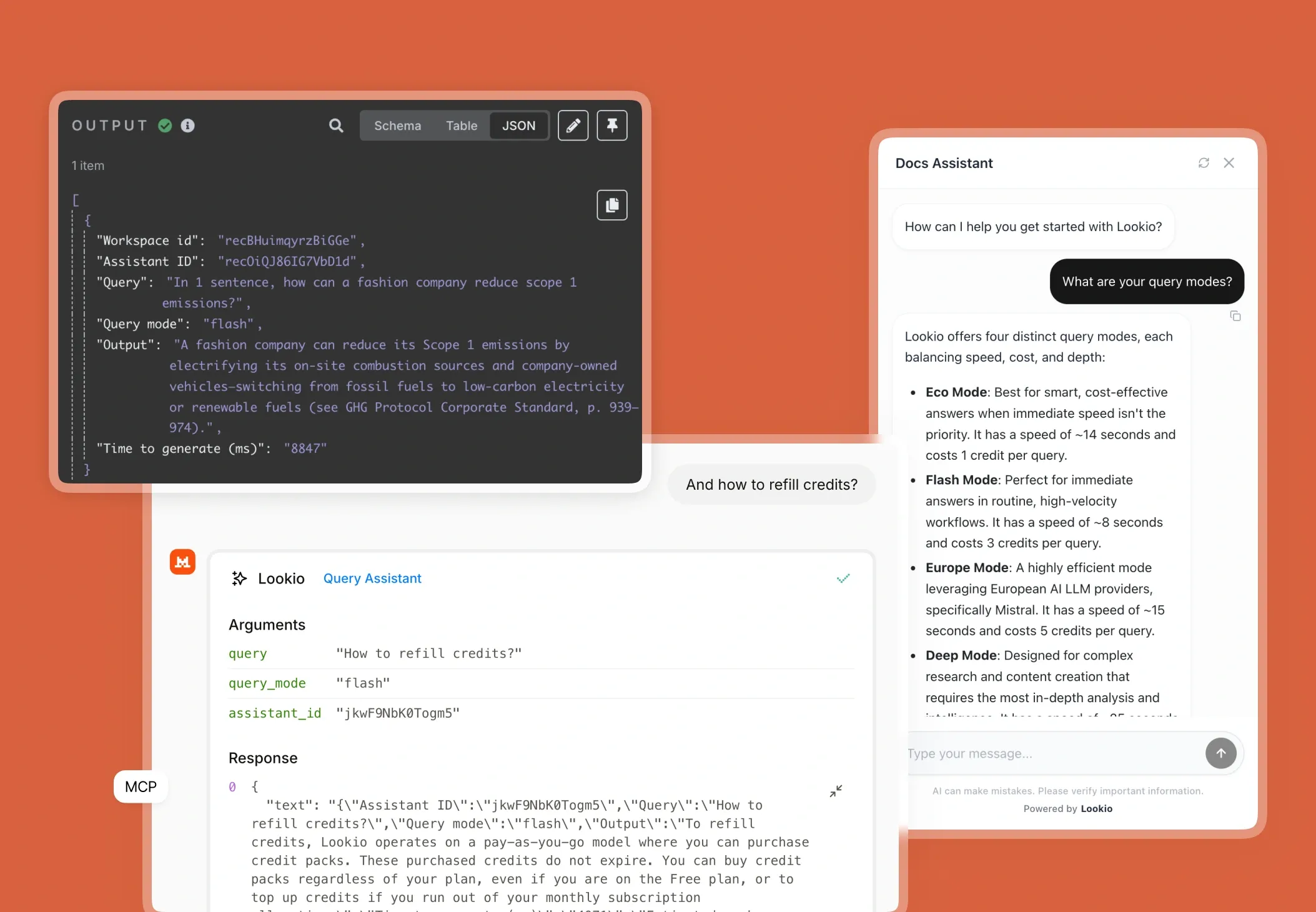
What's missing is a programmatic brain that lives alongside your code, serving up verified truths without the manual overhead.