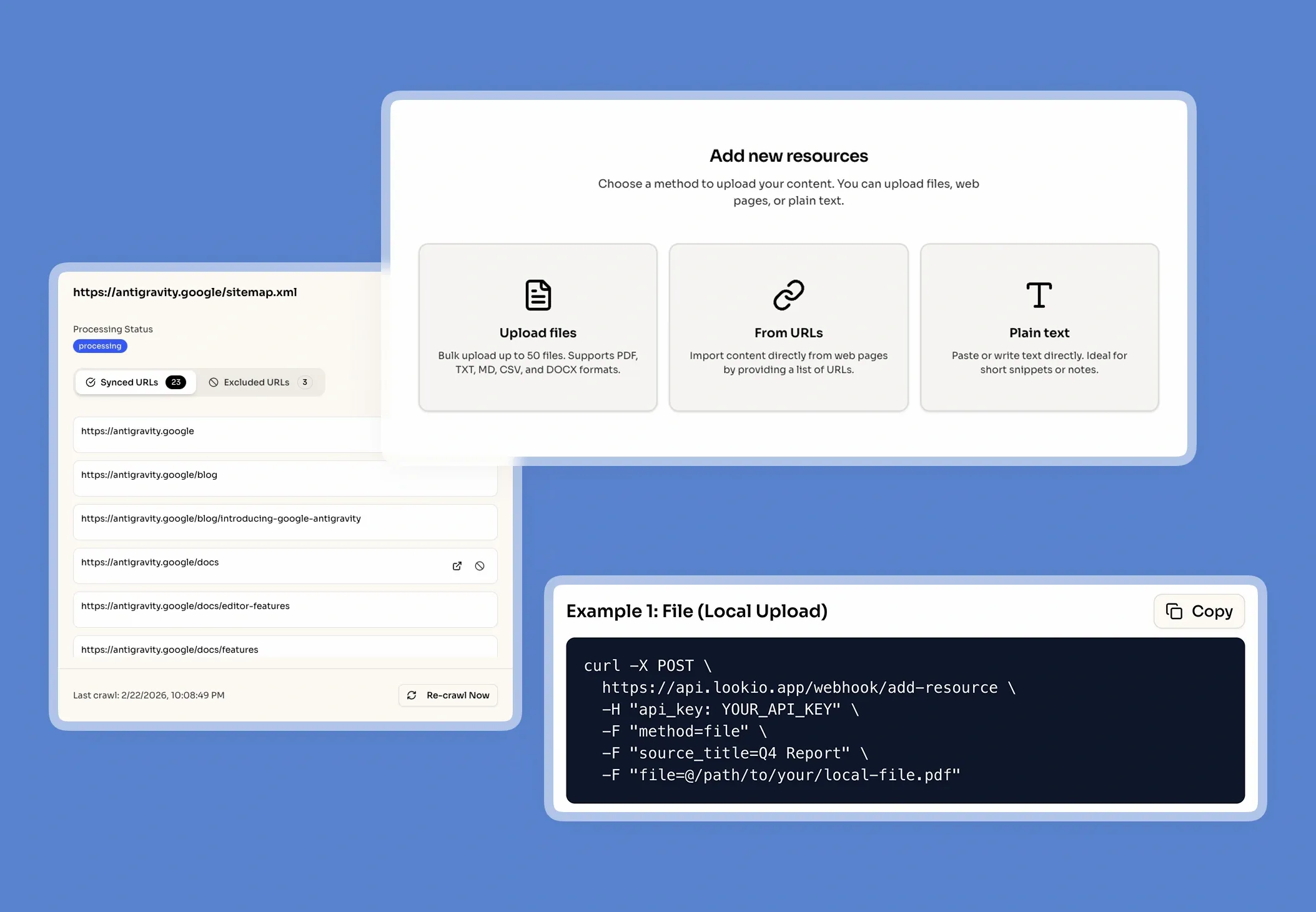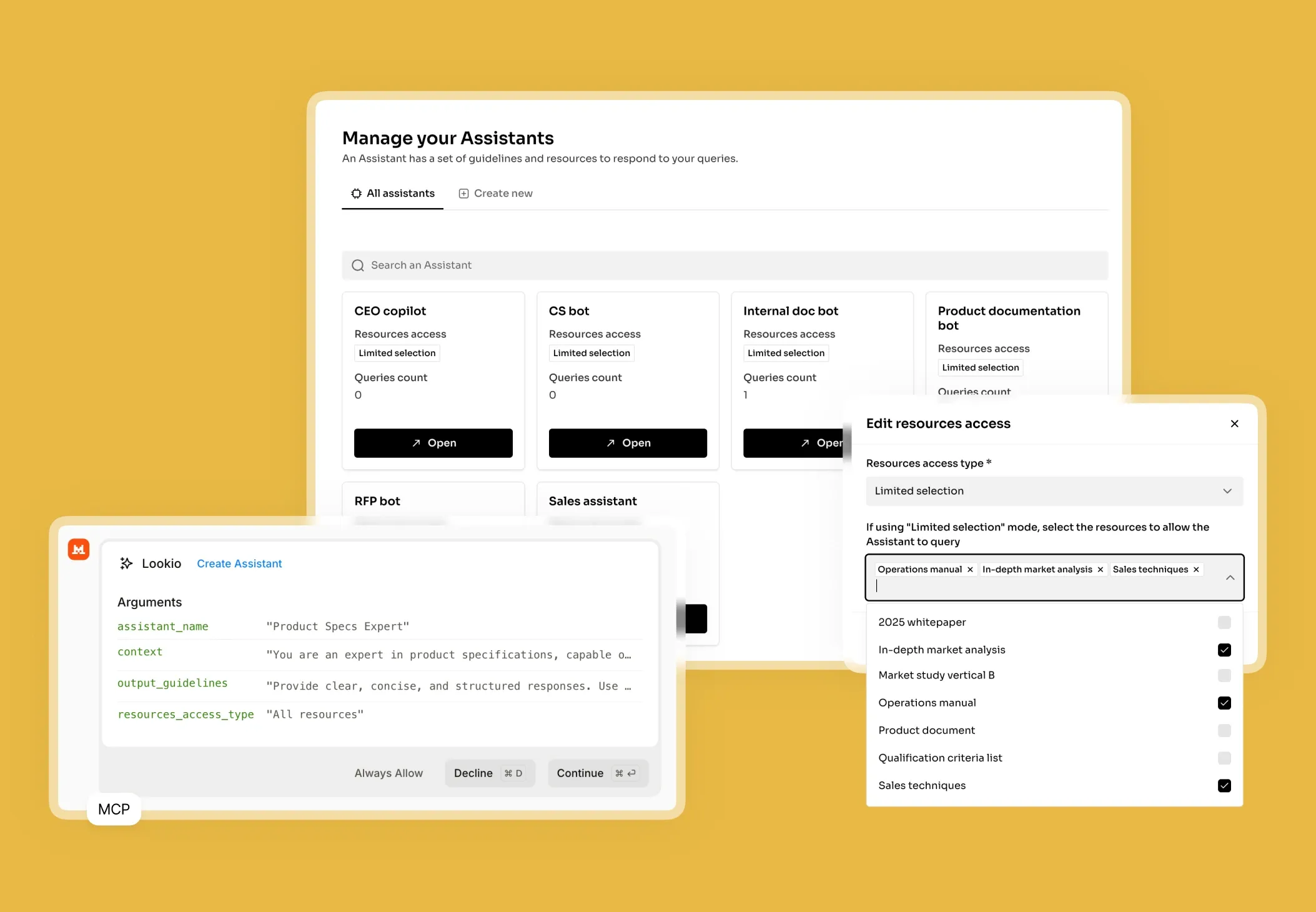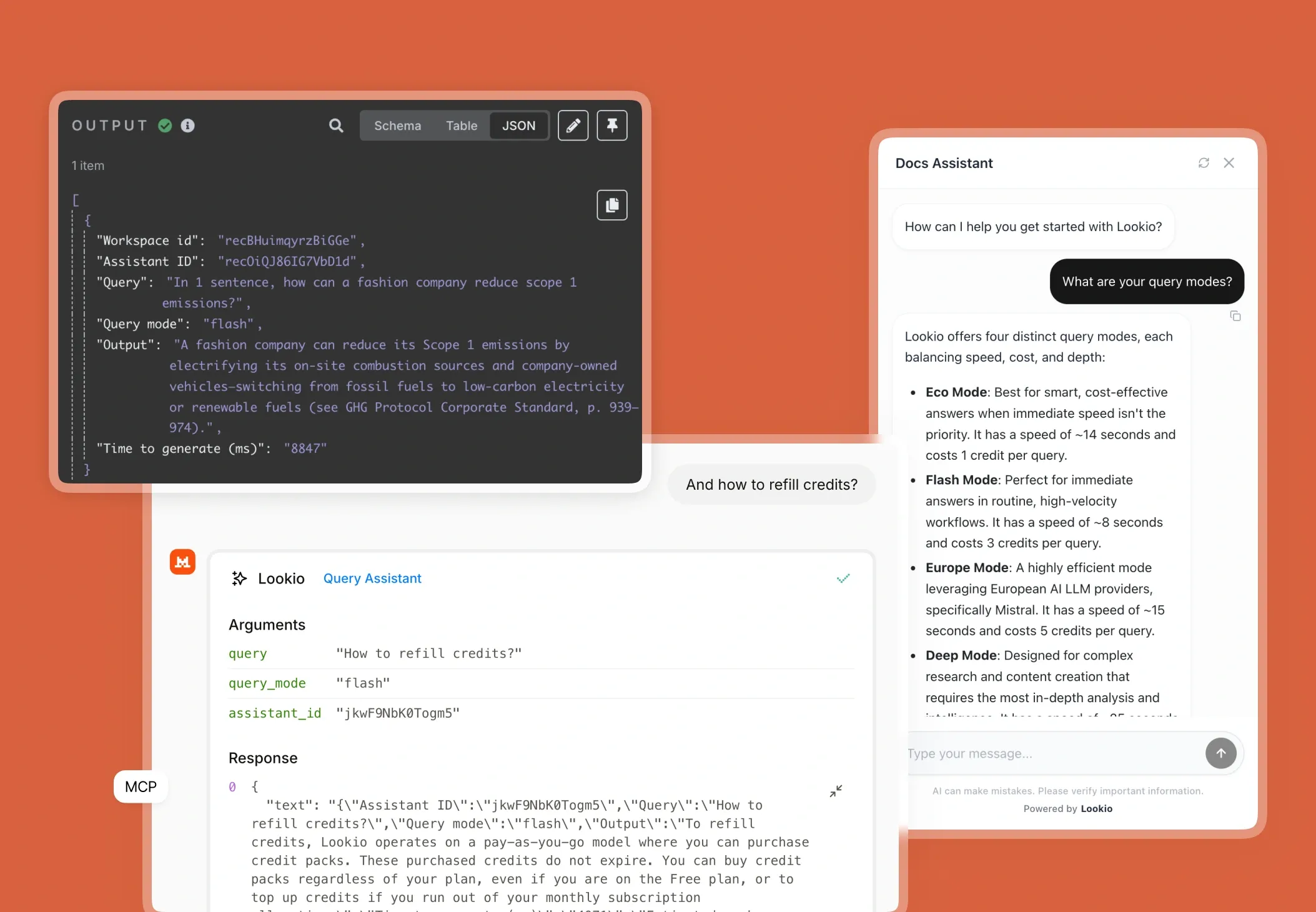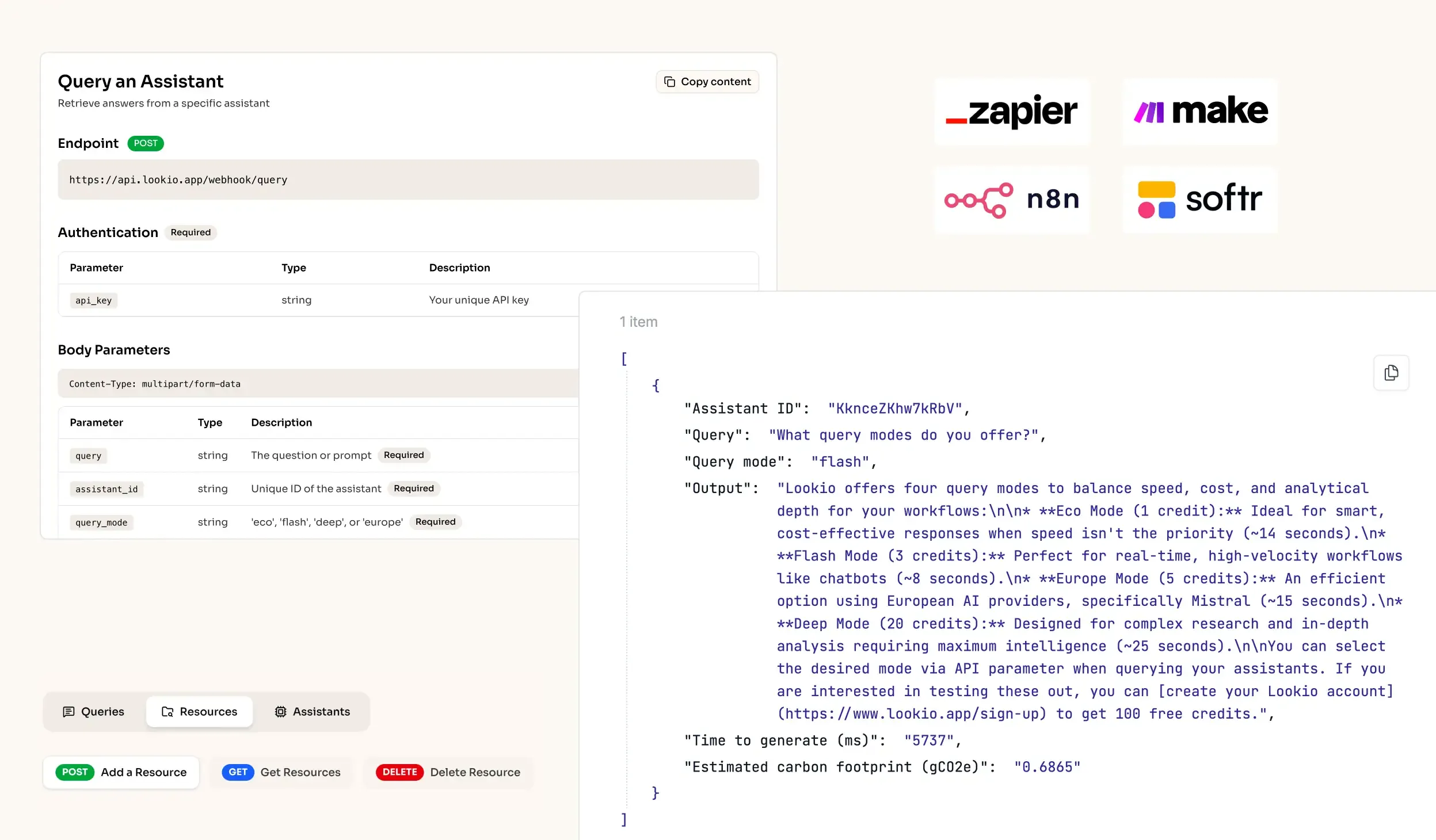
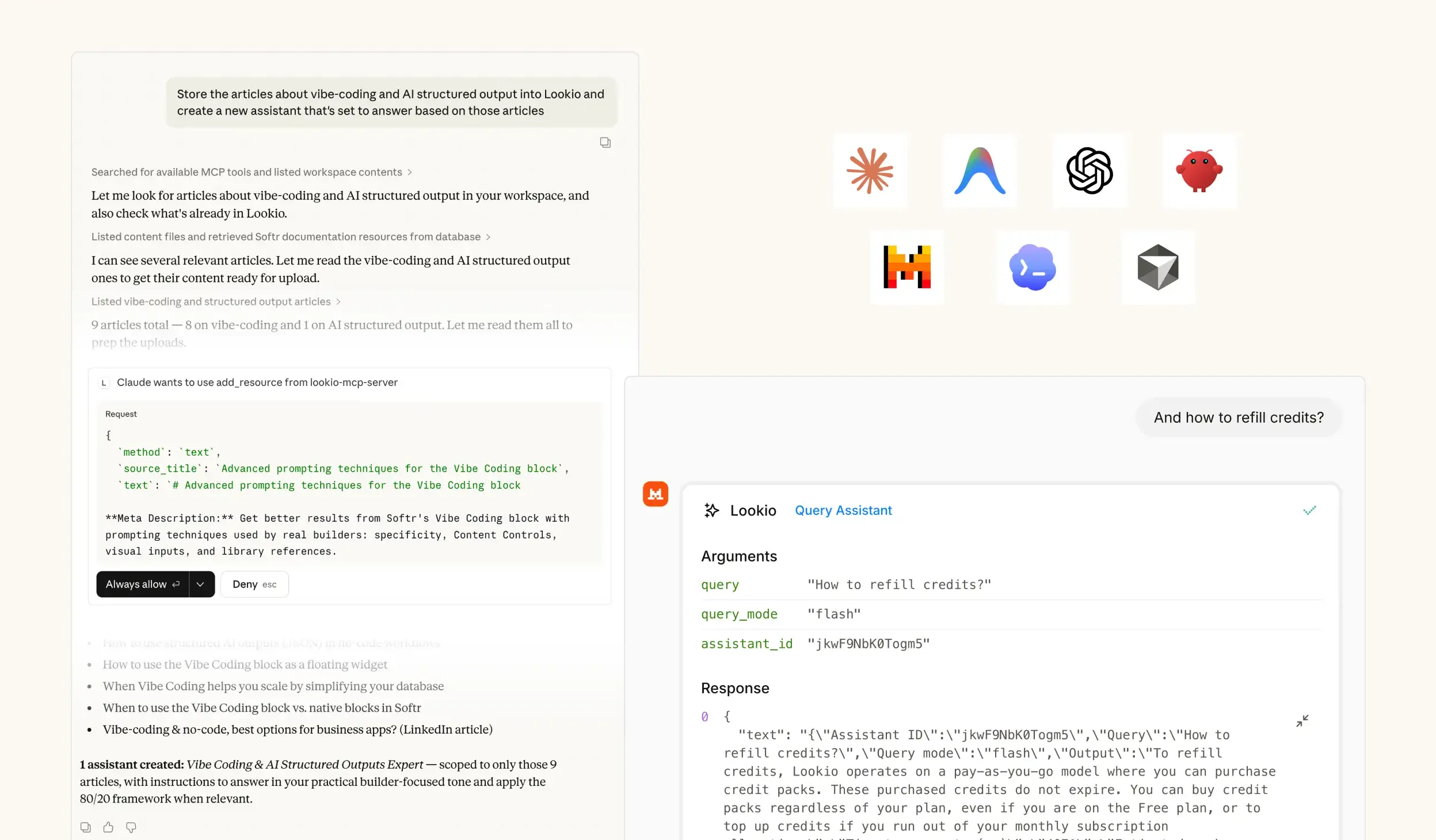
The challenge of managing massive editorial archives
When an editor at a publishing house needs to verify a detail in a historical manuscript or cross-reference a specific style guide rule, they hit a wall of unstructured data. Publishing houses sit on goldmines of proprietary information—ranging from decades of back-catalogs and author correspondence to complex legal contracts and internal metadata. However, this knowledge is often trapped in inconsistent PDFs, old Docx files, or scattered internal wikis.
The daily cost of metadata silos
What breaks in the current workflow is human memory reliance. When a marketing team needs to find unique insights from a 500-page biography to write a promotional blog post, they usually spend hours skimming text or bothering the original editor. This leads to SLA risks in production, quality gaps in marketing copy, and a constant drain on your most senior staff. The business impact is clear: your most valuable asset—your unique information—is costing you time rather than generating it.
Why the tools they've tried fall short
Most publishing teams have already experimented with basic solutions, only to find they don't scale to the needs of professional media:
- Manual search and DAM tools: Keyword matching fails when you don't know the exact term. It can't handle the conceptual queries typical of editorial research.
- Generic AI (ChatGPT): Tools like ChatGPT suffer from the "lost in the middle" phenomenon and frequently hallucinate fictional details about your books, creating a massive liability for factual accuracy.
- No-API tools like NotebookLM: While helpful for an individual editor, NotebookLM lacks an API, making it impossible to integrate into a house's automated distribution or CMS workflow.
What's missing is a way to turn static archives into a programmatic brain that responds with sourced, verified data every time.