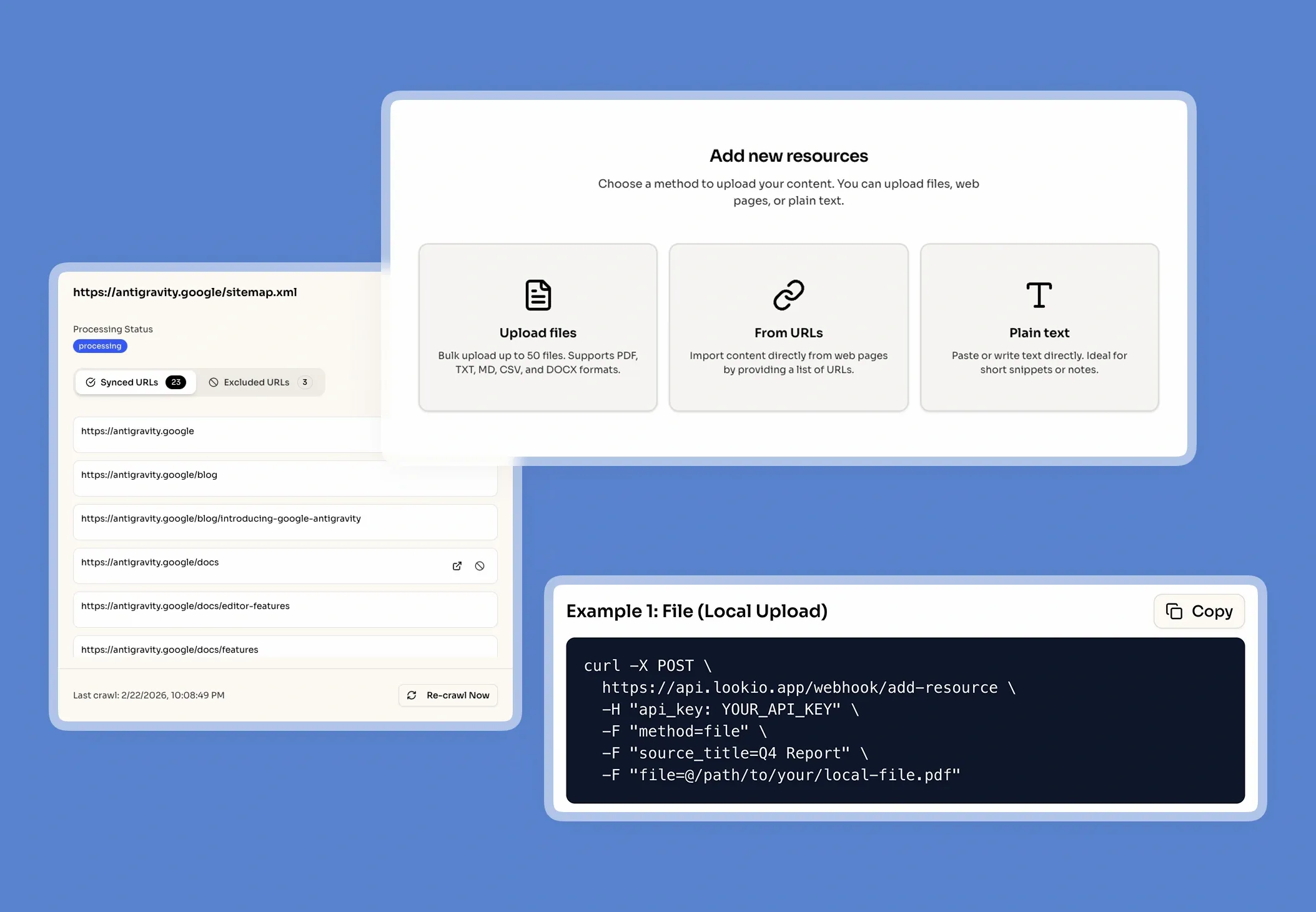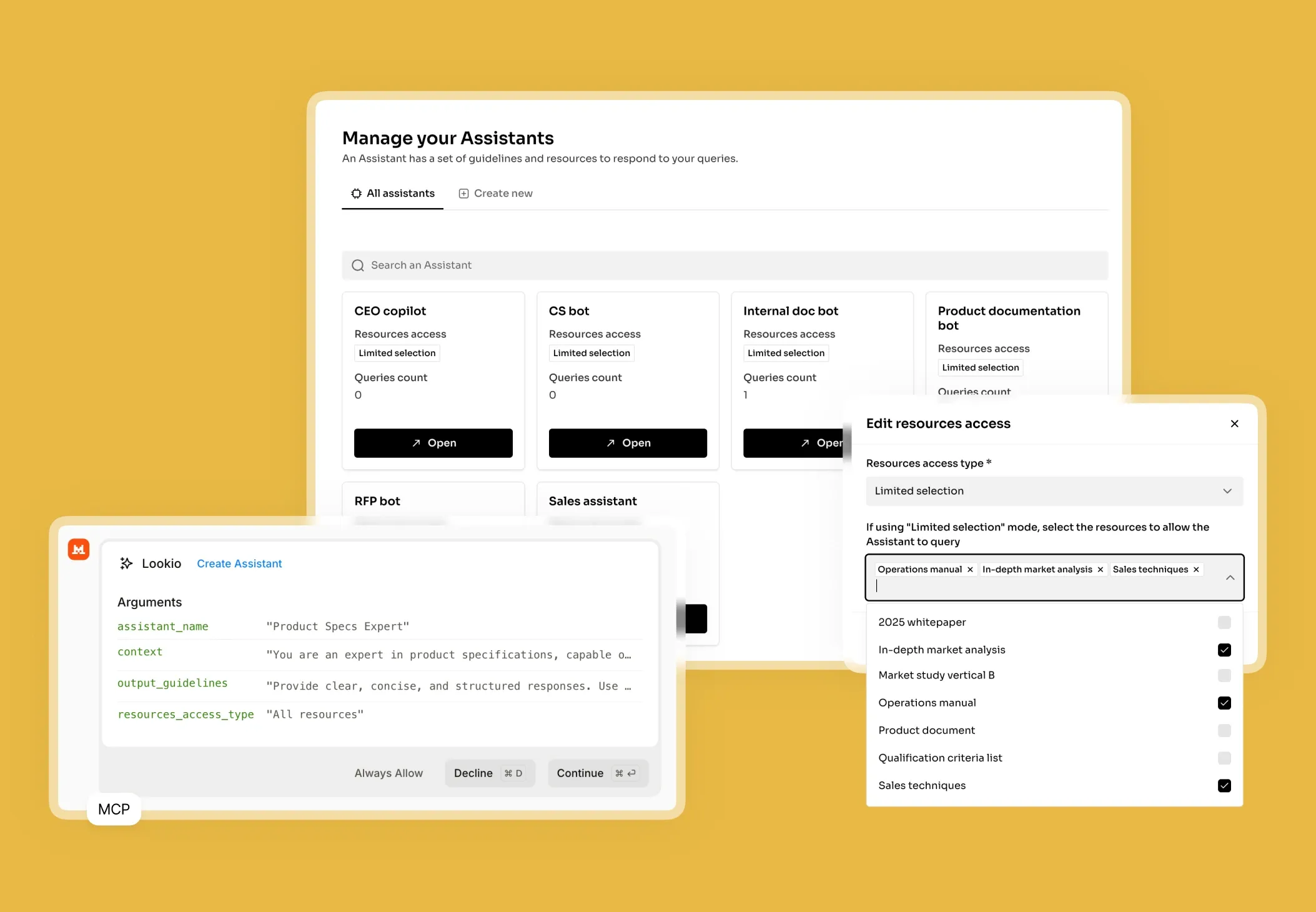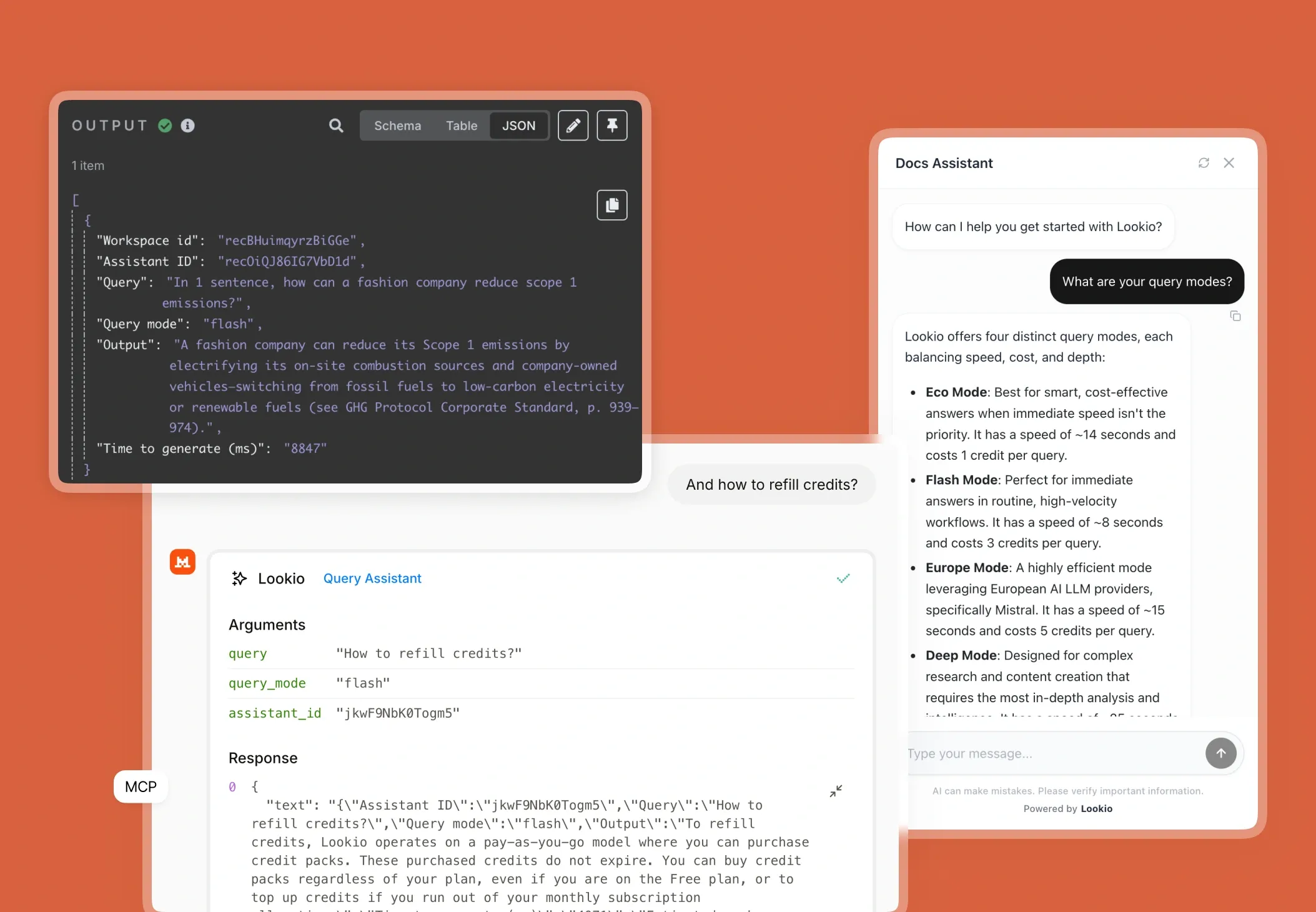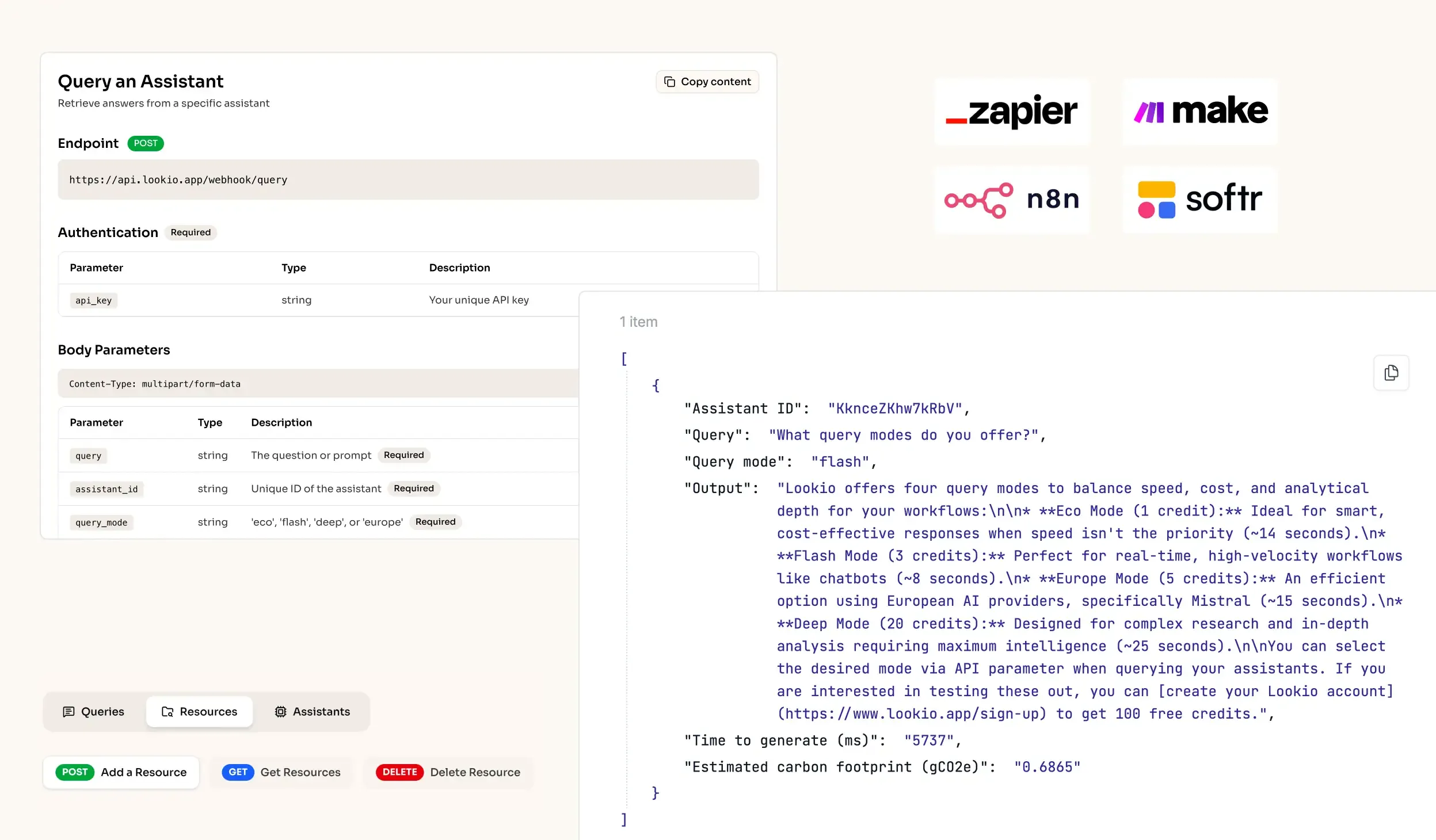
The challenge of scaling benchmarking studies
When a market researcher or data analyst tries to extract competitive insights from a mountain of disparate reports, they hit a wall of manual processing. Benchmarking isn't just about reading; it's about comparing specific KPIs, methodologies, and growth rates across hundreds of pages of PDF reports, financial statements, and industry whitepapers. As your library grows, the ability to find that one specific data point from a 2022 competitor filing becomes a needle-in-a-haystack problem.
The daily cost of document fatigue
In a typical benchmarking workflow, the bottleneck is rarely the analysis itself—it's the data retrieval. Experts spend hours command-F searching through documents, leading to missed insights and significant SLA risks for client deliverables. When high-value consultants are stuck doing manual data entry instead of strategic interpretation, the business scalability collapses. Without a centralized way to query this collective intelligence, every new study starts from zero, ignoring the wealth of data already sitting in your archives.
Why the tools they've tried fall short
Most teams attempt to solve this with standard search tools, but these fail at the last mile. Manual search and internal wikis rely on keyword matching; if a report uses the term "Operating Margin" but you search for "EBITDA," basic tools will miss it entirely.
Generic AI like ChatGPT initially feels like a savior, but it quickly becomes a liability. These models often hallucinate specific numbers when they can't find them, and their token limits collapse when you try to feed them ten 50-page PDFs at once. Furthermore, tools like NotebookLM lack an API, meaning you cannot automate your benchmarking. In a professional environment, you can't afford a tool that lives in a silo. What's missing is a programmatic bridge between your raw documents and your final report.